Self Localization
The research fields of humanoid robots embody multiple aspects and disciplines from mechanical engineering up to artificial intelligence. The physical composition and appearance of humanoids differentiate them from the rest of the robots according to their application domain. The physical composition will ultimately allow the robots to uninvasively, properly and effectively interact and operate within human-centered environments. The integrated skills of sensing and acting endowed by reasoning and learning mechanism enables humanoid robots to perform advanced tasks in a flexible and adaptive manner.
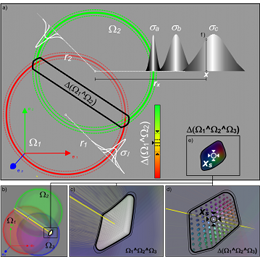
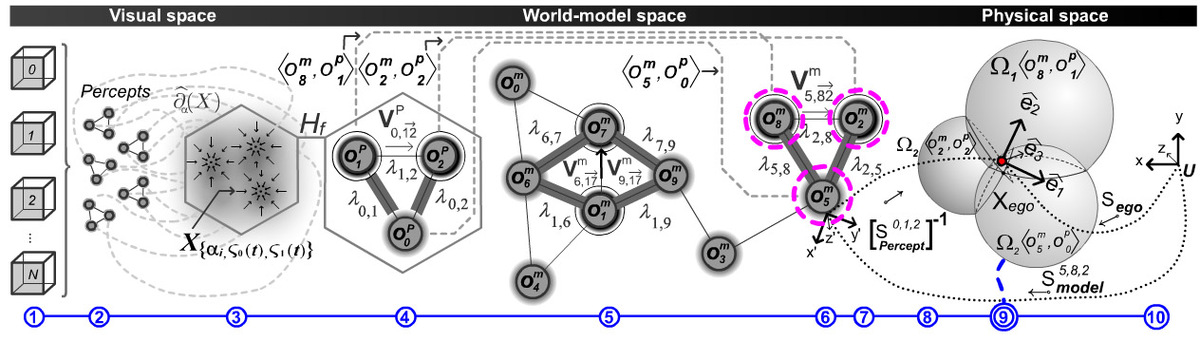
The perception cycle bridges the real with the modeled world and it plays a fundamental role for humanoids. This cycle is responsible for the sensor management, their signals and the extraction of valuable information from raw-data up to symbolic instances of the modeled world. The endeavor of this visual perception cycle is to acquire and to track necessary signals and symbols in order to robustly, precisely and rapidly solve assertion queries arising either at the planning or reasoning layers. The fundamental perception capabilities are:
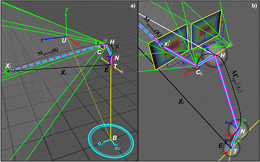
- Self-Localization: Acquire and track the position and orientation of the humanoid by means of active stereoscopic vision;
- Model-Based Global Localization
- Model and Appearance Based Dynamic Localization
- Environmental Status Assertion: Solve visual queries about the status of the environment throughout task execution;
- Pose Queries: 6D pose of environmental element
- Trajectory Queries: Propercetive and perceptive trajectory for dynamic transformations
The quality of these capabilities depends on real-time performance with a compelling robustness. The link from the world-model to the signals provided from the cameras represents the vision-to-model coupling, whereas its counterpart the model-to-vision coupling concerns with the inference and prospective anticipation mechanisms which allow the extraction of clues, priming models to bottom up information and profit from model-based segmentation. Both couplings act in conjunction in order to provide a visual space perception, i.e. an autonomous visual framework for real-time vision applications on humanoids. The necessary methods for such a framework do not only require novel active-vision methods and action-vision techniques, but they also formulate and conduct concrete concepts and implementation of essential cognitive aspects for a model-based humanoid vision system. The framework considers the whole execution cycle of complex tasks for a humanoid from the start-up global localization, where the vision-to-model coupling is acquired for the first time, followed by the dynamic localization where the 6D pose of the humanoid has to be tracked in order to ensure the updated vision-to-model coupling. Furthermore, the framework must be able to provide support for all modules which require information from the visual space, e.g. the global task planner, reasoning and learning mechanism.